
Overview
The SparkThink API provides SparkThink users with programmatic access to the functions and data from their SparkThink surveys and workshop projects. SparkThink users may use the SparkThink API to automatically display newly updated SparkThink data on a data visualization dashboard, or integrate SparkThink into their business workflow by triggering/scheduling actions from an external system.
Introduction to GraphQL
The SparkThink API is based on GraphQL. GraphQL is a query language for APIs that gives you a high-level of flexibility to specify in your API requests what data you need, and get back exactly what you asked for.
A regular REST or SOAP API is very well structured and specifically defined. The endpoints have their set requests and responses and that’s what you get whether or not that matches your usage pattern. GraphQL lets you control all of this so that the way you consume the data matches exactly what you need.
In GraphQL, there are only two types of operations you can perform: queries and mutations.
- While queries are used fetch data, mutations are used to modify server-side data.
- If queries are the GraphQL equivalent to
GETcalls inREST, then mutations represent the state-changing methods in REST (likeDELETE,PUT,PATCH, etc).
To learn more about GraphQL, check out the official GraphQL.org documentation hosted by the Linux Foundation.
Obtaining a Service Account
About Service Accounts
In order to use the SparkThink API, you will need a service account. Service accounts are special accounts that can be used by the SparkThink application to access SparkThink APIs programmatically.
How it works
Each Service Account is defined by a Client ID and a Client Secret. You will need both pieces of information to obtain a JSON Web Token (or Bearer Token), which is then used to authenticate with the SparkThink API.
Your Service Account has special privileges, so be sure to keep them secure. Do not sure your Service Account ID or Access Code with anybody else or on any publicly accessible area, like Github, client-side code etc.
How to request a Service Account
You can submit a request for a SparkThink Service Account via the following methods:
- Create a ticket at https://support.slalom.com
- Email us at sparkthink@slalom.com
- Contact us on Teams
Service Accounts currently have a 1 year expiration, and will need to be extended after that time by the SparkThink Team.
Authentication Endpoint
The SparkThink API uses a JSON Web Token (or Bearer Token) to authenticate any API request. You will need to request a bearer token using your Service Account.
Production Endpoint for Authentication: https://shift.slalom.com/api/authenticate/serviceaccount/{clientId}
HTTP Method: POST
Header: Content-Type: application/json
Data:
{"clientSecret": "clientSecret"}Here is an example:
curl \
-H "Content-Type: application/json" \
--request POST \
-d '{"clientSecret": "clientSecret"}' \
"https://shift.slalom.com/api/authenticate/serviceaccount/{clientId}"
API Endpoints
When you make an API call, you should use the following pattern:
Production Endpoint for API calls: https://shift.slalom.com/graphql
HTTP Method: POST
Header: {"Authorization: Bearer ACCESS_TOKEN"}
JSON: {'query': query_questions}
Here's an example:
$ curl -X POST -H "Authorization: Bearer ACCESS_TOKEN" -H "Content-Type: application/graphql" https://shift.slalom.com/graphql --data '
{
project(id: "62586b8b361cd30046843760", type: Survey){
id
title
}
}'Permissions
Each SparkThink Service Account is setup to replicate the access of a specific SparkThink user. As a result, the SparkThink projects that the Service Account can read or write will be those projects that the SparkThink user (associated with the Service Account) has created or has been added as an administrator.
Pagination
Some queries may return a huge number of results, which may take a long time to return or may even timeout. SparkThink API uses cursor-based pagination, which allows the API user to traverse a large set of results. This pattern is used for data sets that may be potentially large, such as survey responses and respondents collections.
This type of pagination uses fields named edges and pageInfo. Edge types must have fields named node and cursor. The actual data is contained with each node object. The cursor object is used to store the page offset, and a PageInfo object to identify an hasNextPage object.
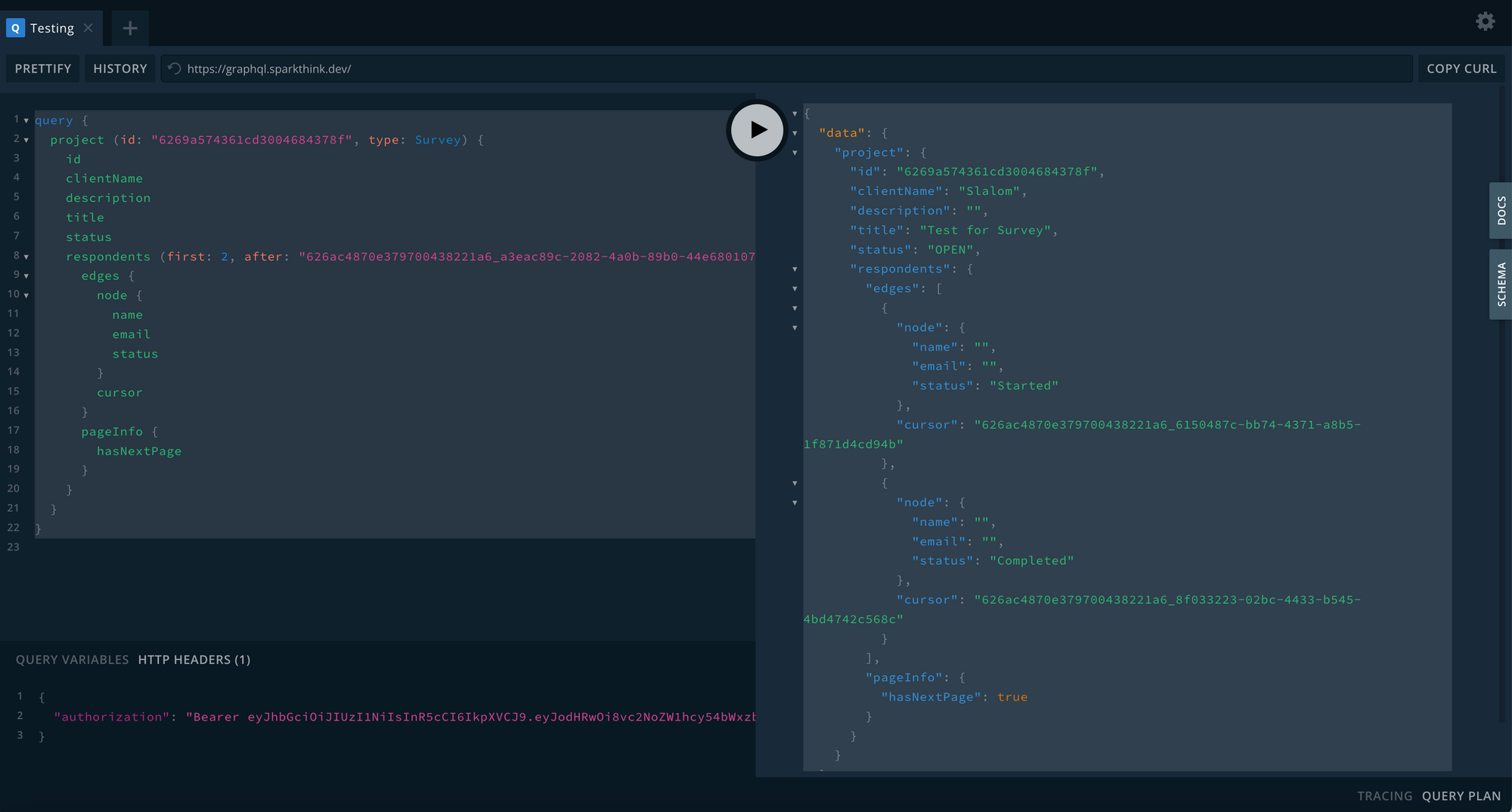
Here is an example of a project respondents query that uses pagination.
query {
project (id: "6269a574361cd3004684378f", type: Survey) {
id
clientName
description
title
status
respondents (first: 2, after: "626ac4870e379700438221a6_a3eac89c-2082-4a0b-89b0-44e680107bfc"){
edges {
node {
name
email
status
}
cursor
}
pageInfo {
hasNextPage
}
}
}
}
Here is the example response:
{
"data": {
"project": {
"id": "6269a574361cd3004684378f",
"clientName": "Slalom",
"description": "",
"title": "Test for Survey",
"status": "OPEN",
"respondents": {
"edges": [
{
"node": {
"name": "",
"email": "",
"status": "Started"
},
"cursor": "626ac4870e379700438221a6_6150487c-bb74-4371-a8b5-1f871d4cd94b"
},
{
"node": {
"name": "",
"email": "",
"status": "Completed"
},
"cursor": "626ac4870e379700438221a6_8f033223-02bc-4433-b545-4bd4742c568c"
}
],
"pageInfo": {
"hasNextPage": true
}
}
}
}
}
Check out this GraphQL.org article to learn more about pagination.
Playground
We have a playground environment that is pointed to the SparkThink Development Environment. You can write your own queries based off the data that in the Development environment.
Here’s how you can get started:
- Open the GraphQL playground: https://graphql.sparkthink.dev/
- Open https://sparkthink-dev.slalom.com/admin/home
- Open Developer Tools > Network
- Click one of the resources named “All” that has an “authorization” string in the header
- Copy the authorization string into the “HTTP Headers” section in the GraphQL playground
- Write your query or mutation
- Click the play button to run the query or mutation
Further Support
- Create a ticket at https://support.slalom.com
- Email us at sparkthink@slalom.com
- Contact us on Teams

